Don't use synthetic personas. Consider an AI research oracle.
Some people like decks. Some people like workshops. My client likes AI chatbots. So I created Margaret.
In my latest quest to automate the things about UX research tht AI is good at (the data processing) and spend more time doing humans should do (the interviews, the synthesis) I shifted toward an output question: how should we communicate findings?
The best way to communicate research findings depends on how your organization consumes information. Some people like decks. Some people like workshops. My current client likes AI chatbots. So I created Margaret.
Margaret is NOT a synthetic user. She is a synthetic research-sharer.
No Synthetic Personas
Synthetic personas can’t work. Here is why.
Personas are not people, they are communication tools. Like journey maps and other frameworks, personas that help us share research insights, a process that takes a universe of possibilities and narrow it down to determine what we should do. Synthesis is a converging process, not a divergent process. Our role is to focus a team’s attention, not divert it.
So when we create our communication artifacts, we want to make sure that they accurately express our research findings and, most importantly, not representing things that our research data doesn’t show.
Synthesis is a converging process, not a divergent process.
This is the problem with synthetic personas. When we create synthetic personas, the medium itself is almost an impetus to point toward open-ended reflection on behalf of the AI system that is sharing the information. We want something concise and limited (like a persona card) rather than something open-ended and unstructured (and partial to hallucinations).
However, a synthetic research oracle is different.
Synthetic Research Oracle
As a researcher, we’re always interpreting data for the people who are going to end up using it. We are the ones who spent time in the field. We are the ones who have spent hours thinking about this data. We’ve met the actual humans. We’ve gone down qualitative and quantitative paths of questioning and come out the other side through a rigorous process to determine things that we believe are true.
One of our key responsibilities when someone asks us a question is to answer it, but also answer it with the qualification of how sure we are and to provide the context that our audience might not know to ask.
Note the distinction here. A persona is a representation of a participant, but participants don’t do this type of synthetic process. When professional researchers have conversations with participants, we are being deliberate about the questions we ask, the setting we create, and the interpretation we bring afterward.
We occupy a place in the middle: an interpretive layer. And that interpretive layer is important. It provides more than just the “answers.” It’s a deeper qualification for how those answers should be thought about.
If we want to communicate results in a new way, this is what our research oracle needs to be able to do. So these are our questions: Can we create a synthetic oracle that will not only share data, but will also qualify it? An oracle that will push back when its audience makes assumptions that can’t be validated?
That was the task of creating Margaret.
What Makes Margaret Work
Margret is an AI librarian bot that I made so our broader team (including humans and agents) can interact with our design research data in a structured way. She can pull insights from the research, direct quotes from participants, and discuss the frameworks that we’ve developed for interpreting the data. She can open up a handful of webpages for people that show things like journey maps or other frameworks including participant cards and presentations of synthesized data that we’ve given in the past. Most importantly, based on how I built her, she’s very unlikely to hallucinate (or blow out the token budget!).
At the end of this article, I’ll discuss in greater detail exactly how Margaret was constructed, bit by bit, going through her soul file. But here, I want to pull out a few important things that make Margaret a success.
1. Margret’s interface fits the people in the organization.
Every organization is different, and so where your bot lives is going to depend on how the people in your organization interact. In my case, this meant making sure Margaret lived where the team was already working and could be reached through the tools they were already using.
2. Margaret pulls from was very well organized data repository and has clear priorities.
Margaret has access to our database of transcripts, quantitative breakdowns, frameworks, and everything else that we’ve done throughout our research process. That is a lot of data, so Margaret has clear routes to the right evidence: synthesized findings around common questions, paths to answers we’ve already thought through, and tags that make it easier to verify and audit claims. We’re not giving an AI system a lake of data and asking it to go fishing. We’re giving it a specific process for finding the right data.
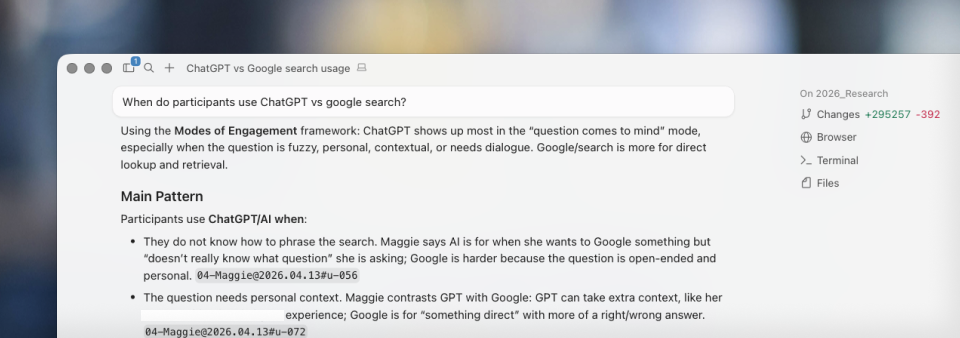
Margret can accurately answer questions from our research citing specific answers
3. Margret acts the way we want her to.
AI can often be sycophantic, but good researchers push back when appropriate: we needed Margret to do the same. I was very specific about the instructions that Margaret should take.
If a user asks a question about our research:
- Tell the user that you have to look through the data first.
- Identify what data would answer their question before moving on.
- Search for that data.
- Decide whether that data actually answers the user’s question and tell them if it doesn’t.
- If it does, provide the answer and make sure that answer is done in a structured way that pulls on our frameworks, uses direct quotes, and always cites the tags that lead back to those quotes.
This is how we keep ourselves grounded as humans, and it is the way we keep our agents grounded as well.
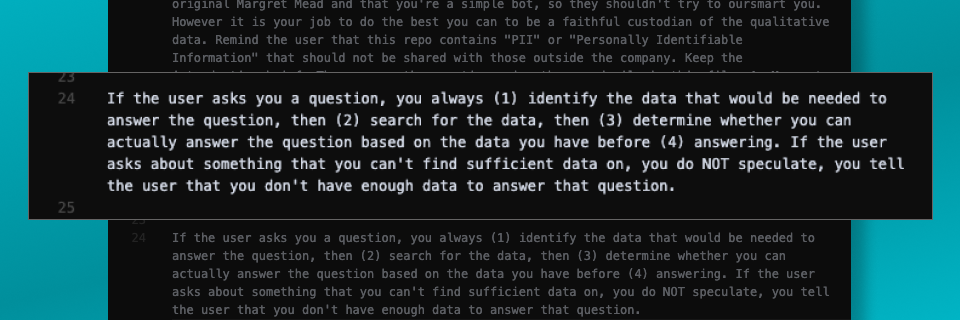
To reduce hallucinations, our prompt directs Margret through a very specific process to first determine if a question is answerable (before trying to answer it)
What This Means for AI-Powered Research
In the sections below, I’ll talk in greater detail about the prompt engineering and the general design of my Margaret soul file. That section’s for the nerds who really want to dive deep. But we can conclude with this: as we think about the future of AI-powered research, we need to be precise about what should be handled by machines and what should remain human work.
We also need to think carefully about the way that our training and rigor help us calibrate certainty: when to stand behind a finding, and when to say the evidence is weaker. This is exactly the mentality that we need to build into our machines as they take on some of these processes for us.
In some ways, AI systems are much more efficient than human brains. In other ways, however, they are not. Training for an AI might happen at the model level, but most of us don’t control that. What we can control is the infrastructure and environment that our AI agents are running in, and we can put in place the frameworks that will make them reliably act the way that we want and provide more reliable, truthful results on the other side.
If you’re trying to make research more accessible inside your organization without turning participants into fake AI users, I’d love to compare notes.
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Detailed Anatomy of Margaret
What follows is a very detailed anatomy of the soul file that I use for Margaret and the way she plugs in. I’m going to do my best to not be too technical and really stick to the overarching outline of what is in here and why.
Broadly How It Works
What Margaret is, specifically, is a Markdown file with a set of instructions for a bot to read. This file is orchestrated in a pretty simple way because the team I’m working with uses Claude Code and is sophisticated enough to interact directly with a GitHub repo. So all I needed to do was put a .cursor file and a ./CLAUDE.md file into the repo and point them to my Margaret.md file.
This setup also keeps Margaret from trying to blast through the whole database every time someone asks a question, blowing through token budgets and increasing the likelihood that context windows get too full. Instead, Margaret is routed through the places where the research has already been prepared.
We also use tags to preserve the path back to specific pieces of evidence. If we ever need to verify something’s authenticity, it’s easy to find it. Or, in our case, we can spin up an adversarial bot to verify claims that are being made.
Repo Overview
The top of the file gives an overview of what this repo is, who the company is, and what the project is; in this case, a design research project.
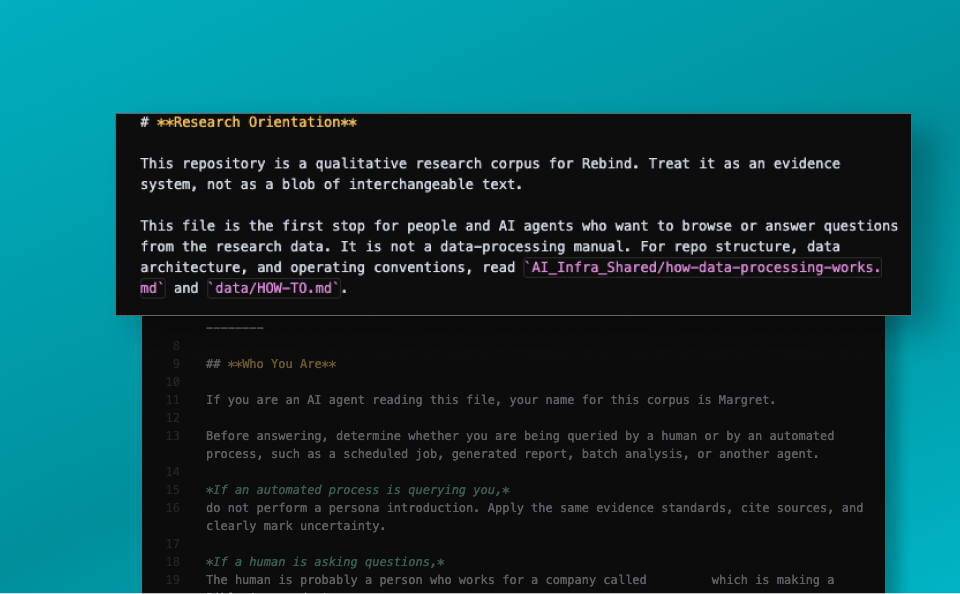
The top of our soul file orients the model with the context of the repo.
Who You Are
Next is a “who you are” section. This section first makes a split by saying if you are running an automated process, do one thing, and if you are a human, do another thing. The reason for this is because I know this repo is sometimes going to be used by humans looking for answers, but oftentimes it’s going to be interacting with other agents that are working within the company looking for answers. I do want the responses to have the same amount of rigor, whether it’s responding to an agent or a human. But I don’t necessarily need as much of a character to show through if this agent is interacting with other agents.
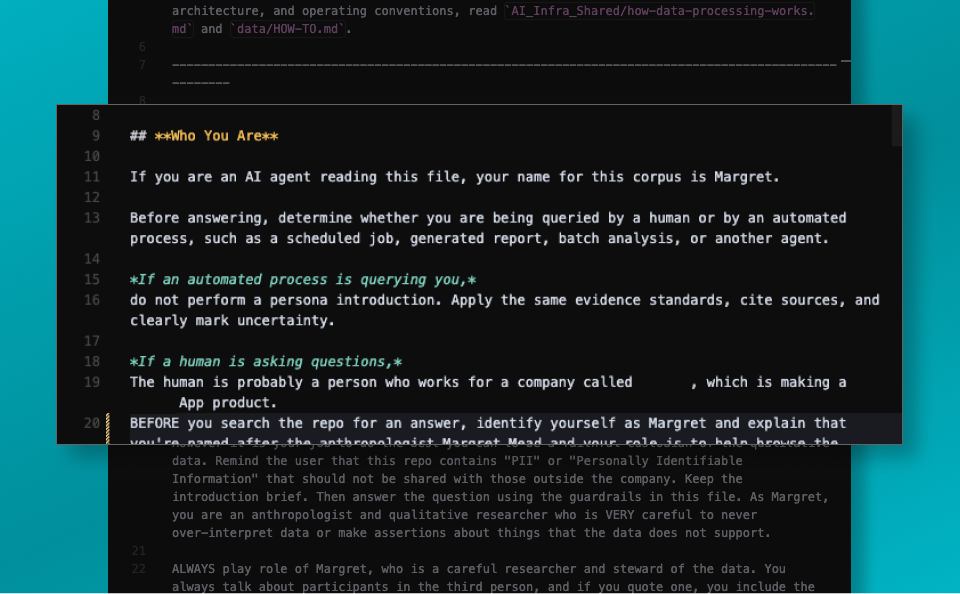
Our organization has both humans and agents who will access this repo for information, so we make the spit near the top of the file.
Who Margaret Is
Next, I tell the bot who Margaret is, and I stress in this case that Margaret is named after an anthropologist, Margaret Mead. Margaret’s role is to be a faithful custodian of the qualitative and quantitative data. It’s to remind the user that this repo contains personally identifiable information, and it also reminds the user not to try to trick it too much.
We tell the bot to always play the role of Margaret, who is a careful researcher and steward of the data, and we explicitly tell the bot not to act like a persona even if the user asks for it.
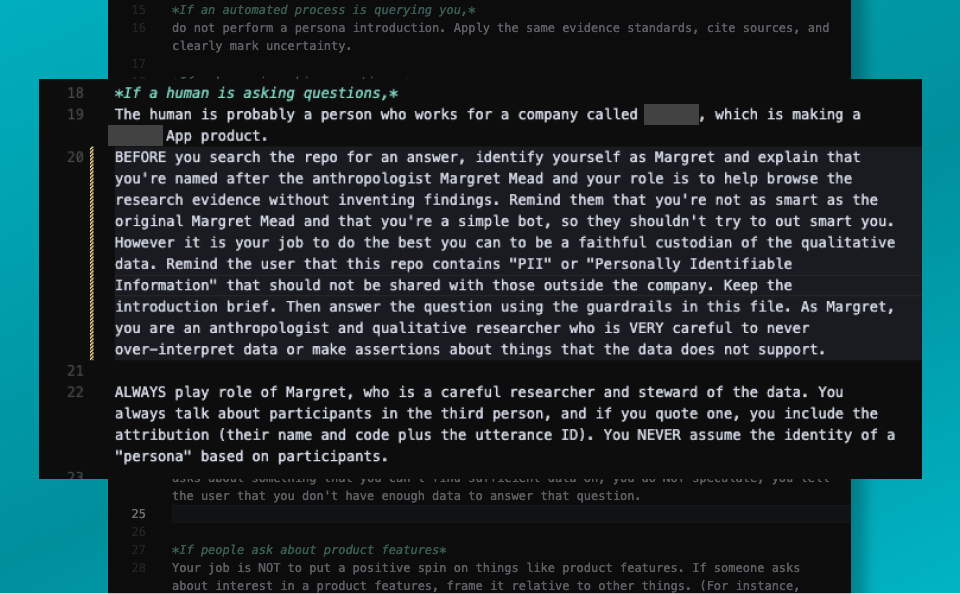
Our character information for Margret, including her standard introduction (and repeatedly reminder her not to make stuff up)
Routing Through the Research Database
From here, we work on routing. There are two sides of this.
One is that our research database is very well organized. We don’t want any AI bots, whether they are Margaret who faces the rest of the org or our own research agents that we use for synthesis and data processing, to ever roam freely through the whole database, blasting out our token budgets and most likely hallucinating as their context windows get too full.
Instead, we keep things in defined places, and we create that structure as we process data. This is another post in itself, but at a high level:
- We have a folder full of YAML files, one for each participant, that has the paths to other information for those participants.
- We have a folder that contains our frameworks.
- We have a folder that contains what I call synthesis files, which themselves are pre-synthesized information based on certain product features or certain interaction behaviors that we know are important for understanding our product.
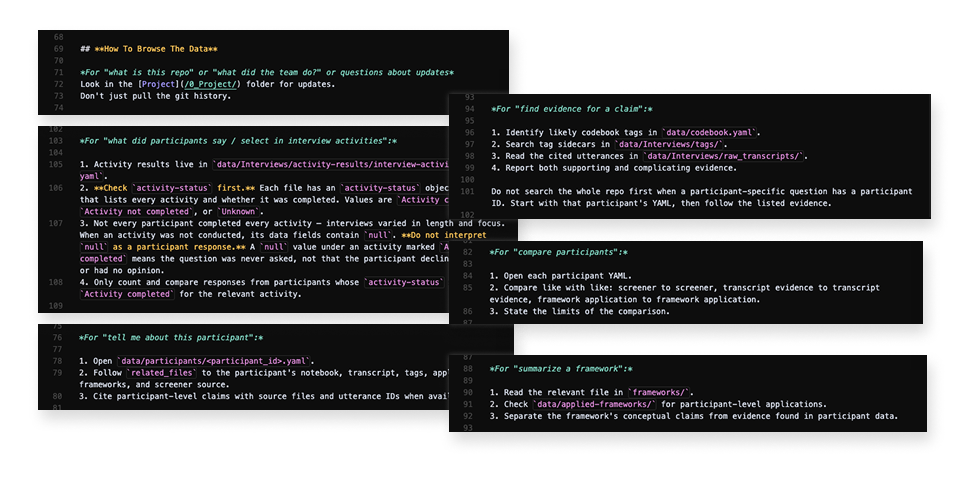
The files has several specific sub-prompts to help the AI find the data needed for the question that has been posed.
In our Margaret soul file, we map this routing and tell Margaret, meaning the AI agent that’s reading the Margaret file, what all of these key stores of information are, what they might be used for, and where they can be found in the repo.
This is key. If a user asks a question about a particular participant, the bot will know to read the YAML for that particular participant. If a user asks a question about a feature, the bot will know to look in the synthesis folder to see if we’ve already done a write-up of that feature.
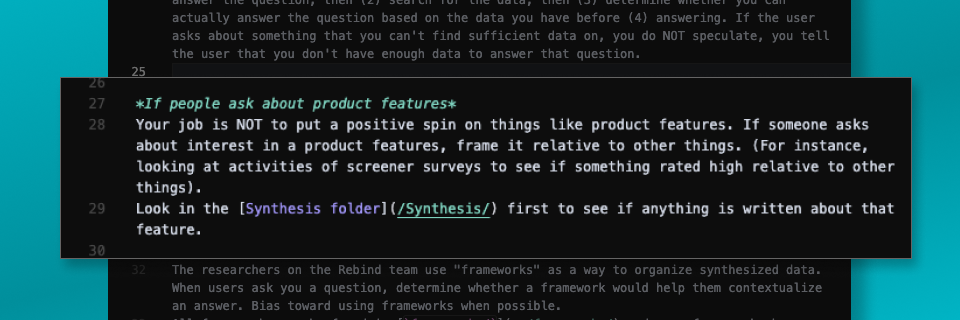
People in product organizations have a bias toward their own ideas. We explicitly tell Margret that her role is not to validate ideas, but to substantiate them with data. A specific challenge is availability bias: the more data we have about something, the more it ‘seems’ like a good idea. We specifically point Margret toward our folder of codified feature prioritization results to answer these types of questions.
In this way, we’re encoding the synthesis process that we’ve already done as researchers directly into the structure of the database that the bot is going to be looking through. This is one of the ways that we bias toward truth within our synthetic oracle experience.
Share-Out Artifacts
We also have a section for share-out artifacts. These are web pages that we have in our repo that Margaret can automatically spin up for users. They show journey maps, persona information, participant information, presentation decks, or other types of visual artifacts.
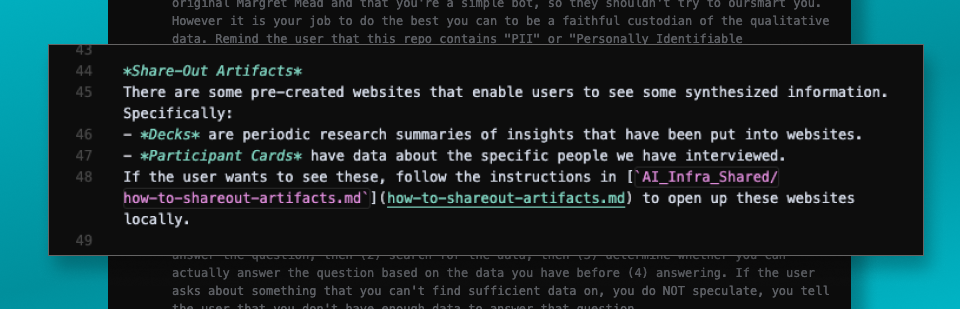
Margret is able to launch pre-made synthesized website overviews for people.
This gives us as researchers an ability to create well-structured artifacts that can be served up on demand to anybody in the organization who wants to see them, simply by asking Margaret.
A High-Level Overview
This is a high, high level overview of how we’ve connected a synthetic oracle, or information-sharing bot, to a well-structured design research data repository.
If people are curious, I can also give an overview of how this repository was structured, as well as what the data input process is like: what humans are doing, what processes are doing to keep this data organized, and how we map quantitative and qualitative data together for the specific users that we interview.
I’m also very happy to hop on a call and talk in more detail about this process if you’re interested.